Dernière mise à jour : 10/10/2022
Toute l'actualité du Centre Tesnière
🎓 Soutenances de mémoire - Session 2

La deuxième session des soutenances des mémoires des étudiants en Master TAL a lieu le lundi 30 juin à partir de 9h au Salon Préclin.
Les étudiants qui soutiennent en présentiels sont tenus d'arriver 15 minutes avant l'ouverture de la session.
Thèse : Panggih Kusuma Ningrum, Identifying and Annotating Scientific Uncertainty in Scholarly Texts: Methods, Frameworks, and Applications

Nous avons le plaisir d'annoncer la soutenance de thèse de notre doctorante Panggih Kusuma Ningrum qui se tiendra le mercredi 11 juin à 14h au Grand Salon (site Mégevand, Université Marie et Louis Pasteur). La thèse s'intitul "Identifier et annoter l’incertitude scientifique dans les textes académiques : méthodes, cadres et applications" et est dirigée par Iana Atanassova et Philipp Mayr-Schlegel. Le jury sera composé de :
- Professeur Frommholz, Ingo, Modul University (Autriche) Rapporteur
- Professeur Roche, Christophe, LISTIC, Université de Savoie Mont Blanc (France) Examinateur
- Professeur Labbé, Cyril, LIG, Université de Grenoble Alpes (France) Rapporteur
- Docteure Atanassova, Iana CRIT, Université Marie et Louis Pasteur ; IUF (France) Directrice de thèse
- Docteur Dr Mayr-Schlegel, Philipp GESIS, Leibniz Institute for the Social Sciences (Allemagne) Codirecteur de thèse
Résumé de la thèse :
L’incertitude scientifique est au cœur du processus de recherche et de la construction de nouvelles connaissances. Cette thèse explore la manière dont l’incertitude est exprimée dans les textes académiques, en abordant les défis liés à son identification et à sa classification. Premièrement, la majorité des corpus annotés existants se concentrent sur des aspects spécifiques de l’incertitude — tels que l’atténuation (hedging), la négation ou la modalité — sans parvenir à en saisir toute la diversité à travers les disciplines scientifiques. Deuxièmement, la détection de l’incertitude scientifique est une tâche complexe à cause de la polysémie des indices linguistiques d’incertitude, dont le sens peut varier selon le contexte. Les approches antérieures ont souvent négligé le contexte linguistique et sémantique, ce qui peut entraîner des erreurs de classification. Troisièmement, l’expression de l’incertitude est linguistiquement complexe, stylistiquement variable, et peut dépendre des auteurs et des disciplines.
Pour relever ces défis, ce travail propose : 1) un cadre d’annotation à cinq dimensions pour catégoriser l’incertitude de manière exhaustive ; 2) un corpus de référence annoté, comprenant 2,523 phrases extraites de 22 revues en sciences, technologies et médecine (STM) ainsi qu’en sciences humaines et sociales (SHS), et de 53 revues issues du dépôt SSOAR (Social Science Open Access Repository). Ce corpus constitue une ressource précieuse pour l’entraînement et l’évaluation de modèles de détection de l’incertitude, en assurant la reproductibilité des résultats et en rendant possible les recherches futures ; 3) un système appelé UnScientify, qui permet de détecter et d’annoter automatiquement l’incertitude scientifique dans des domaines variés. UnScientify est interprétable, efficace, et offre de bonnes performances tout en nécessitant peu de données annotées, ce qui en fait un outil adapté à des applications concrètes. En s’appuyant sur des motifs et des règles prédéfinis, le système atteint une précision et un rappel élevés, surpassant les grands modèles de langage (GMLs), avec une exactitude de 0,816, une précision de 0,952 pour les étiquettes de non-incertitude, et un rappel de 0,956 pour les étiquettes d’incertitude. Une validation externe a confirmé l’applicabilité du système à d’autres corpus, avec une amélioration de l’exactitude (0,841) et un rappel équilibré (0,803 pour l’incertitude, 0,885 pour la non-incertitude).
Note : La soutenance se déroulera en anglais.
📚 Séminaire TAL - Dernier rendez-vous mardi prochain
La dernière session du séminaire de cette année se tiendra le 📅 Mardi 08 Avril à 13h30 en visio via 📍 https://rdv4.rendez-vous.renater.fr/seminaire-tal
🎤 Intervenante : Justine Salvadori, Postdoctorante en linguistique française à l'Université de Fribourg
📖 Titre : L’ambiguïté des noms déverbaux en français : une approche empirique et quantitative
Résumé :
À l’interface de la morphologie dérivationnelle et de la sémantique lexicale, cette étude examine l’ambiguïté des noms dérivés de verbes en français (p. ex. construire > construction, couver > couveuse, emballer > emballage, graver > gravure, sécher > séchoir). Son objectif est de décrire la fréquence, la distribution et l’organisation systémique des schémas de polysémie régulière observés dans le lexique déverbal, tels que ÉVÉNEMENT/RÉSULTAT (construction ‘action de construire’/‘objet construit’), AGENT/INSTRUMENT (accordeur ‘personne qui accorde’/‘appareil pour accorder’) ou encore LIEU/INSTRUMENT (urinoir ‘local’/‘appareil sanitaire’).
Sur le plan méthodologique, l’étude s’appuie sur une base de données inédite et de grande ampleur, fruit du travail de neuf chercheur·euses, qui a été spécifiquement conçue pour l’analyse de la sémantique des noms déverbaux en français (Huyghe et al., soumis). Elle met également à profit deux méthodes quantitatives encore peu exploitées en morphologie dérivationnelle : l’analyse de règles d’association (Agrawal et al., 1993) et l’analyse de réseau (Wasserman & Faust, 1994 ; Zweig, 2016 ; Newman, 2018).
Les résultats dévoilent un nombre substantiel d’associations sémantiques régulières, non aléatoires et orientées, dont la majorité semble motivée par des relations métonymiques. Alors que certains schémas sont bien documentés (par ex. ÉVÉNEMENT à RÉSULTAT), d’autres se révèlent inédits (par ex. ÉVÉNEMENT à ÉVÉNEMENT COLLECTIF, comme dans bousculade ‘action de bousculer’/‘remous de foule’). Les associations identifiées peuvent en outre être bipartites ou tripartites (par ex. ÉVÉNEMENT/INSTRUMENT/RÉSULTAT), ce qui suggère que l’ambiguïté dans la nominalisation est structurée par des micro-paradigmes sémantiques. Enfin, l’analyse de réseau révèle que l’ambiguïté déverbale suit une organisation très hiérarchisée, prenant la forme d’une structure en étoile centrée sur le type sémantique événementiel.
Dans l’ensemble, cette recherche propose une nouvelle perspective empirique sur la polysémie des noms déverbaux (cf. Melloni, 2011 ; Rainer, 2014 ; Lieber, 2018), en éclairant ses mécanismes sous-jacents et son organisation systémique.
Références
Agrawal, R., Imieliński, T., & Swami, A. (1993). Mining association rules between sets of items in large databases. SIGMOD Record, 22(2), 207-216.
Huyghe, R., Salvadori, J., Varvara, R., Barque, L., Haas, P., Lombard, A., Monney, M., Tribout, D., & Wauquier, M. (soumis). SONDE: A database for exploring the semantics of nouns derived from verbs in French.
Lieber, R. (2018). Nominalization: General overview and theoretical issues. In M. Aronoff (Éd.), Oxford research encyclopedia of linguistics. Oxford University Press.
Melloni, C. (2011). Event and result nominals. A morpho-semantic approach. Peter Lang.
Newman, M. (2018). Networks (2e éd.). Oxford University Press.
Rainer, F. (2014). Polysemy in derivation. In R. Lieber & P. Štekauer (Éd.), The Oxford handbook of derivational morphology (p. 338-353). Oxford University Press.
Wasserman, S., & Faust, K. (1994). Social network analysis: Methods and applications. Cambridge University Press.
Zweig, K. A. (2016). Network analysis literacy: A practical approach to the analysis of networks. Springer.
Ce séminaire est ouvert à tout.e.s., nous vous attentons nombreux !
📚✨ Séminaire TAL - Prochain rendez-vous ce vendredi
Le séminaire de cette semaine se tiendra le 📅 Vendredi 04 Avril à 🕒 13h au 📍 Salon Préclin
🎤Intervenante : Aurélie Nomblot, Doctorante en TAL à l'école doctorale LECLA (CRIT, UMLP)
📖 Titre : Des langues naturelles aux langues inventées : génération automatique de langues immersives
Résumé :
Nous explorons dans cette recherche la génération automatique de langues inventées immersives, c’est-à-dire des langues perçues comme réalistes, cohérentes avec des univers fictionnels et capables de transmettre des impressions spécifiques. Le processus de création de telles langues étant long et complexe, nous avons conçu un générateur nommé Euphoniae 1.0 pour accompagner et automatiser cette tâche.
La présentation reviendra sur les règles linguistiques intégrées au générateur, construites à partir de structures observées dans les langues naturelles, de principes issus du symbolisme phonétique et de lexiques adaptés aux contextes narratifs. Enfin, le fonctionnement du générateur sera présenté, avant d’aborder l’analyse des résultats obtenus ainsi que les limites observées.
Ce séminaire est ouvert à tout.e.s., nous vous attentons nombreux !
📚✨ Séminaire TAL - Rendez-vous le mardi 25 mars
Le séminaire de la semaine prochaine se tiendra le 📅 Mardi 25 Mars à 🕒 13h au 📍 Grand Salon
🎤Intervenants : Pierre Verschueren, Maître de conférences en histoire contemporaine au Centre Lucien Febvre (UMLP)
📖 Titre :Le projet ès lettres : quels corpus et quels méthodes pour une histoire longue de la thèse de doctorat ?
Résumé :
Ès lettres est un projet d’étude et de valorisation des thèses de doctorat ès lettres soutenues en France au XIXe siècle. Il part du constat qu'au sein du système universitaire tel qu’il se cristallise au courant du XIXe siècle le doctorat, acquiert une importance spécifique, d’une part comme certifiant la capacité à produire des savoirs nouveaux, d’autre part comme barrière et niveau régulant l’accès au corps universitaire lui-même. Il se trouve ainsi à l’interface entre le système de production des savoirs scientifiques et le système de reproduction des élites intellectuelles, et constitue un observatoire de l’institutionnalisation des disciplines. Et pourtant, il reste à ce jour très peu exploré par l’historiographie, par manque d’outils pour aborder une documentation à la fois massive et dispersée. Le projet entend dès lors rassembler des informations relatives à ces documents, actuellement dispersées entre de multiples sources, puis à procéder à la numérisation de ces thèses tout en préparant celle de documents qui leur sont associés (notamment les rapports de soutenance) ; s'ajoute à cela la constitution d'une base de données prosopographique en ligne (https://eslettres.bis-sorbonne.fr/).
Ce séminaire est ouvert à tout.e.s., nous vous attentons nombreux !
🎉 Notre doctorante en Finale Régionale de "Ma thèse en 180 secondes" !
Aurélie Nombot en Finale Régionale de "Ma thèse en 180 secondes" !C'est avec une immense fierté que nous annonçons la participation d'Aurélie Nombot, doctorante en 4ème année à l'école doctorale LECLA de l'Université Marie et Louis Pasteur, à la finale régionale du concours Ma thèse en 180 secondes.
Aurélie, qui prépare sa thèse au Laboratoire C.R.I.T. dans le domaine du TAL, saisit cette opportunité pour rendre ses recherches sur le sujet des Langues inventées accessibles au grand public.
Le concours "Ma thèse en 180 secondes" invite les doctorants à présenter leurs travaux de recherche en trois minutes chrono, de manière claire, passionnante et sans jargon technique. Chaque participant dispose d'une seule diapositive pour captiver l'audience.
Cette année, la Finale régionale se déroulera au théâtre de Montbéliard, MA scène nationale, le 20 mars 2025. Dix finalistes s’affronteront pour tenter de remporter le Prix du jury et le Prix du public.
Nous vous invitons chaleureusement à venir soutenir Aurélie et les autres finalistes le 20 mars 2025 au théâtre de Montbéliard !

📚✨ Séminaire TAL - Prochain rendez-vous le vendredi 21 mars
La prochaine session de séminaire se tiendra le 📅 Vendredi 21 Mars à 🕒 14h au 📍 Grand Salon
🎤Intervenants : Johanna Cordova, Ingénieure de Recherche (ERTIM, INALCO) et Postdoctorante en TAL à l'Université de Pau et des Pays de l'Adour
📖 Titre :Traitement automatique d’une langue peu dotée : l’exemple du quechua
Résumé :
Les grands modèles de langues (LLMs) ne couvrent à eux tous qu’environ 12 % des langues écrites. Alors qu’un intérêt croissant est porté aux langues minoritaires dans le TAL, nous nous poserons les questions suivantes : dans quelle mesure est-il possible de développer des outils de TAL « état de l’art » pour des langues peu dotées étant donné la faible quantité de ressources textuelles disponibles dans ces langues ? Quelles sont les problématiques qui surgissent lorsqu’on souhaite développer des outils de TAL dans ce contexte ? Nous prendrons pour illustrer notre propos l’exemple du quechua, macrolangue parlée par plus de 6 millions de locuteurs à travers sept pays d’Amérique du Sud, mais qui dispose d’une faible présence numérique. De la numérisation de ressources au développement d’un analyseur morphologique, nous détaillerons la méthodologie employée pour doter cette langue, tout en nous intéressant à sa morphologie complexe.
Ce séminaire se tiendra exclusivement en ligne via https://rdv4.rendez-vous.renater.fr/seminaire-tal et est ouvert à tout.e.s.
🎓 Présentations de mémoire - Master 1
La première session des présentations des mémoires des étudiants en première année de Master TAL aura lieu le vendredi 14 mars à partir de 9h au Grand Salon.
📚✨ Séminaire TAL - Prochain rendez-vous ce vendredi
La prochaine session de séminaire se tiendra le 📅Vendredi 21 Février à 🕒9h au 📍Grand Salon
🎤Intervenants : Nicolas Gutehrlé, Post-doctorant en TAL et Iana Atanassova, Directrice du CRIT, Institut Universitaire de France
📖Titre :Etudier l’incertitude dans les articles scientifiques : mise en perspective d’une méthode linguistique
Résumé :
L’incertitude fait partie intégrante du processus de recherche scientifique et est inhérente à la construction de nouvelles connaissances. Dans cet article, nous examinons la manière dont l’incertitude est exprimée dans les articles scientifiques et proposons un cadre d’annotation rendant compte des différentes dimensions de cette notion. L’incertitude scientifique est définie ici comme l’expression d’un manque de connaissance ou d’un manque de précision dans les informations sur un sujet ou un concept identifié. Nous proposons un jeu de données de référence (gold standard), composé de 1 839 phrases d’articles scientifiques annotées manuellement et provenant de plusieurs disciplines. Nous proposons également une approche à base de connaissances linguistiques pour l’annotation automatique des articles et pour la détection et la catégorisation de l’incertitude scientifique. Nous comparons l’efficacité de notre approche en termes de scores de Précision, Rappel et F1 aux méthodes de prompts few-shot réalisées via les Grands Modèles de Langue Phi-3.5 et Llama 3 pour la même tâche d’annotation. Cette évaluation comparative montre des scores similaires entre les approches, allant jusqu’à des scores F1 de 0,858 pour notre approche.
Ce séminaire est ouvert à tout.e.s.
📚✨ Séminaire TAL - Prochain rendez-vous le vendredi 14 février
On se retrouve le 📅Vendredi 14 Février à 🕒9h au 📍Grand Salon pour la prochaine session.
🎤Intervenant : Cyril Bauduret, Directeur Adjoint Pépite BFC
📖Titre : Présentation du Statut National d'Etudiant-Entrepreneur et du dispositif d'accompagnement de Pépite BFC
Pour plus d'informations, cliquez ici.
Ce séminaire est ouvert à tout.e.s.
A la une
Un premier semestre riche en événements pour le département TAL et le Centre Tesnière !
Le semestre dernier s'est achevé avec de belles réussites et une multitude d'activités marquantes :
🎉 Nicolas Gutehrlé, membre du département TAL, a obtenu un post-doctorat au Centre Tesnière, confirmant l'excellence de sa carrière académique.
🏆 Aurélie Nomblot a été récompensée par le prestigieux prix StartThèse pour ses travaux prometteurs.
🌍 Événements de vulgarisation scientifique :
- François-Claude Rey, Iana Atanassova et Nicolas Gutehrlé ont participé à la Fête de la Science, offrant des démonstrations interactives au public.
- Nicolas Gutehrlé a également pris part à la Nuit des Chercheurs, un événement dédié à rendre la science accessible à tous.
- Yagmur Ozturk, doctorante au laboratoire CRIT, a partagé son expérience et ses recherches lors d’une interview avec Radio Campus Besançon, disponible en replay.
Nos étudiant.e.s :
- Présentation des mémoires des étudiants de M1 : une étape clé de leur formation en master TAL, réalisée avec succès.
- Les recrutements de stages des M2 pour le semestre à venir sont en cours, ouvrant la voie à des expériences professionnelles enrichissantes.
✨ Ce premier semestre témoigne de l’engagement et de l’excellence des enseignants-chercheurs et étudiants du département TAL.
Rendez-vous dès maintenant pour encore plus de projets, de recherches et d’événements passionnants. Bonne année et bonne reprise à tout.e.s !
📚✨ Séminaire TAL - Prochain rendez-vous ce vendredi
🎤 Intervenant : Natalia Grabar, Chargée de recherche epst au CNRS, UMR 8163 STL à l'Université de Lille
📖 Titre : Rendre les textes médicaux plus accessibles
📅 Date : Vendredi 17 Janvier
🕒 Horaire : 9h - 12h
📍 Lieu : Grand Salon
Résumé :
Différents documents de la vie quotidienne, y compris les documents de santé ou médicaux, peuvent dépasser le niveau de compétence des locuteurs. En effet, les structures syntaxiques, le lexique utilisé, les notions impliquées, la structure de documents, peuvent empêcher la bonne lecture et compréhension de ces documents. Différentes tâches du domaine de TAL (comme le diagnostic de la difficulté ou la simplification), permettent d'adapter ces documents et rendre leur contenu plus simple. Dans ma présentation, je vais décrire ces différentes tâches et leurs résultats. Je vais aussi décrire quelques limites actuelles qui existent dans ce domaine de recherche.
Ce séminaire est ouvert à tout.e.s.
📚✨ Séminaire TAL - Prochain rendez-vous ce vendredi
🎤 Intervenant : Louis-Claude Canon, maître de conférence, Institut FEMTO-ST, Université Bourgogne Franche-Comté, CNRS
📖 Titre : Atelier "Fresque du numérique"
📅 Date : Vendredi 10 Janvier
🕒 Horaire : 9h - 12h
📍 Lieu : B16
Résumé :
La Fresque du Numérique est un atelier ludique et collaboratif d'une demi-journée avec une pédagogie similaire à celle de La Fresque du Climat. Le but de ce "serious game" est de sensibiliser et former les participant·es aux enjeux environnementaux du numérique. L'atelier vise aussi à expliquer les grandes lignes des actions à mettre en place pour évoluer vers un numérique plus soutenable, puis à ouvrir des discussions entre les participant·es sur le sujet. https://www.fresquedunumerique.org/
Ce séminaire est ouvert à tout.e.s.
🎉 Invitation au pot de fin d'année
Pour célébrer la fin du semestre et les fêtes de fin d’année, nous avons le plaisir de vous inviter au pot de fin d'année ! 🎄✨
📅 Date : Mardi 10 décembre
🕒 Heure : À partir de 16h
📍 Lieu :Locaux du Centre Tesnière
Ce moment convivial réunira les étudiants et les enseignants du Master TAL. N’hésitez pas à apporter une petite contribution (boissons, grignotages, gourmandises…). Ensemble, rendons cette rencontre chaleureuse et festive ! 🥂
Nous espérons vous y voir nombreux pour partager ce moment de convivialité et de célébration !
🎙️ Interview en replay sur Radio Campus Besançon : Les métiers de l’enseignement
Nous sommes ravis de vous partager l'interview réalisée avec Radio Campus Besançon dans l’émission "Sortie d’amphi", désormais disponible en replay.
📅 Date de diffusion : 21 novembre 2024
🎧 Replay : Sortie d’amphi : Les métiers de l’enseignement
Lors de cet épisode, retrouvez Yagmur Ozturk, doctorante en 6e année de thèse en Traitement Automatique des Langues.
Dans cet échange captivant, Yagmur partage ses recherches et son expérience de la recherche scientifique.
Début de l'interview : 1h08
À écouter dès maintenant et à partager autour de vous !
Participez à une enquête sur les langues inventées !
Aurélie Nomblot, doctorante au Centre Tesnière, mène actuellement une enquête dans le cadre de sa thèse sur la perception de mots inventés.
Objectif de l’enquête :
Comprendre comment ces mots sont évalués, notamment en termes de leur ressemblance avec des langues existantes, et les impressions qu'ils suscitent. L’enquête est ouverte à toutes les personnes intéressées par l’analyse de listes de mots et prêtes à partager leurs impressions.
Informations pratiques :
- Durée estimée : Environ 10 minutes
- Confidentialité : Toutes les données recueillies seront anonymes et utilisées uniquement à des fins de recherche.
🔗 Lien pour participer : https://forms.gle/L7tXJ6qwy6PUz2g69
Un grand merci pour votre participation et votre soutien à ce projet de recherche ! N’hésitez pas à partager l’enquête autour de vous.
🎉 Félicitations à Aurélie Nomblot pour sa victoire au concours Starthèse !
Nous avons le plaisir d'annoncer qu'Aurélie Nomblot, doctorante au sein de notre équipe, a remporté le prix Créativité lors de la cérémonie de remise des prix du programme national Starthèse, qui s’est tenue le 14 novembre 2024.
Ce concours, porté par le ministère de l’Enseignement supérieur et de la Recherche, vise à encourager les jeunes chercheurs à explorer l’entrepreneuriat en mettant en valeur leurs compétences et leurs travaux de recherche. Il s’adresse aux doctorants et docteurs depuis moins de cinq ans, et cherche à promouvoir des solutions innovanes aux défis sociaux, économiques, culturels et environnemetntaux actuels.
Aurélie a été distinguée pour son projet de générateur de langues, une initiative prometteuse à la croisée de la linguistique et de l’innovation technologique. Ce prix récompense l’ingéniosité et la créativité dont elle a fait preuve dans le développement de ce projet.
Nous félicitons chaleureusement Aurélie pour cette belle reconnaissance de son travail et de son engagement, et nous lui souhaitons plein succès dans la suite de ses recherches et de son parcours entrepreneurial.

Fête de la science

Nous sommes heureux de vous annoncer que le laboratoire CRIT participera à la Fête de la Science cette semaine avec un stand dédié à la découverte des sujets de recherches du laboratoire du CRIT.
📅 Date : Samedi 14 octobre 2024
🕒 Horaires : 14h - 18h
📍 Lieu : Village des sciences sur le Campus de la Bouloie
Venez rencontrer nos chercheurs, explorer nos projets de recherche et découvrir des démonstrations interactives dans une ambiance conviviale et ouverte à tous. Ce sera une excellente occasion de plonger dans l'univers fascinant de la science et d'échanger avec des experts passionnés !
🎟️ Entrée libre et gratuite.
Nous vous attendons nombreux pour une journée de découvertes scientifiques et d’échanges ! Pour plus d’informations, visitez : https://www.fetedelascience.fr/
🧠 La Nuit des Chercheurs approche !
Nous sommes ravis d’annoncer que Nicolas Gutehrlé, notre docteur en post-doc, du département TAL et du laboratoire CRIT participera à cette soirée exceptionnelle dédiée à la vulgarisation scientifique.
📅 Date : Vendredi 27 septembre 2024
🕒 Horaire : 19h - 23h
📍 Lieu : Frac Franche-Comté - Cité des arts de Besançon.
Venez découvrir les dernières avancées en Traitement Automatique des Langues et plonger dans l'univers fascinant de la recherche avec des présentations accessibles à tous. Ne manquez pas cette occasion unique de rencontrer des chercheurs et d'explorer leurs travaux dans une ambiance conviviale et interactive !
🎟️ Entrée gratuite.
Au plaisir de vous y voir nombreux pour une soirée de découverte et d’échange ! Pour plus d'information : https://nuitdeschercheurs-france.eu/

Réunion de rentrée M1 - M2
La réunion de rentrée du master TAL pour l'année 2024-2025 aura lieu le vendredi 06 septembre 2024 à partir de 14h en salle D02.
Phase complémentaire de la campagne de candidatures 2024 pour le Master TAL
Du 25/06/2024 au 30/06/2024 : Dépôt des candidatures sur Mon Master
Retrouvez le calendrier des candidatures ici : Lien calendrier Mon Master.
Pour plus d'informations, consultez https://www.monmaster.gouv.fr/master/universite-de-besancon et contactez iana.atanassova@univ-fcomte.fr.
Thèse : Nicolas Gutehrlé, Extraction d’informations appliquée aux documents non- structurés pour la valorisation de périodiques historiques. Application au patrimoine de la région Bourgogne Franche-Comté en France

Nous avons le plaisir d'annoncer la soutenance de thèse de notre doctorant Nicolas Gutehrlé qui se tiendra le vendredi 21 juin à 14h au Grand Salon (UFR SLHS). La thèse porte sur l'Extraction d’informations appliquée aux documents non- structurés pour la valorisation de périodiques historiques - application au patrimoine de la région Bourgogne Franche-Comté en France et est dirigée par Iana Atanassova. Le jury sera composé de :
- Professeur Bachimont, Bruno COSTECH, Université de technologie de Compiègne (France) Rapporteur
- Docteur Pecina, Pavel ÚFAL, Charles University (République Tchèque) Rapporteur
- Docteur Lamirel, Jean-Charles SYNALP, LORIA, Université de Strasbourg (France) Examinateur
- Professeur Boughanem, Mohand IRIS, Université de Toulouse 3 (France) Examinateur
- Professeur Doucet, Antoine L3i, La Rochelle Université (France) Examinateur
- Professeur Jatowt, Adam Data Science Group, Universität Innsbruck (Autriche) Examinateur
- Docteur ATANASSOVA, Iana CRIT, Université de Franche-Comté, IUF (France) Directrice de thèse
Résumé de la thèse : Ces dernières années, les bibliothèques et archives ont entrepris de nombreuses campagnes de numérisation afin d'élargir l'accès du public à leurs collections d'archives. Cependant, le défi de promouvoir le contenu des collections et de rendre ces ressources accessibles reste entier. La numérisation produit souvent un contenu non structuré dans lequel il est difficile de naviguer, tandis que les interfaces qui s'appuient sur des requêtes basées sur des mots clés pour accéder aux documents d'archives peuvent fournir aux utilisateurs des résultats non pertinents. Afin d'exploiter le potentiel des « Big Data of the Past », notion introduite par Kaplan et di Lenardo en 2017, il est essentiel de développer des méthodes et des cadres pour structurer le contenu textuel des documents, dans le but d’en améliorer l’exploration et l’exploitation. Dans ce contexte, la présente thèse de doctorat aborde le problème du traitement des documents historiques numérisés, en se concentrant sur l'extraction des Entités Nommées et des Relations afin de créer des interfaces pour l'exploitation efficace des données textuelles historiques. Premièrement, nous proposons une nouvelle méthode pour déterminer la structure logique des journaux historiques en utilisant une approche à base de règles. Deuxièmement, nous présentons une méthode pour extraire les entités et les relations concernant les personnes et les lieux mentionnés dans les textes. Notre approche s’intitule Extensible, Lightweight and Interpretable Joint Extraction of Relations and Entities (ELIJERE). Elle est basée sur des ressources linguistiques obtenues par supervision distante. Enfin, nous proposons un cadre général pour l'étude de l'expression d’informations spatiales dans les documents, et un autre cadre pour l'application des méthodes de TimeLine Summarisation à des collections de documents. Nous montrons comment ces méthodes peuvent être appliquées pour produire des interfaces sémantiquement riches, telles que des frises chronologiques et des cartes, qui permettent au grand public une lecture proche ou distante de ces collections.
📰 Présentation du projet EMONTAL dans la revue En Direct !

Le projet EMONTAL, porté par le CRIT et visant à faciliter l’exploration et l’exploitation des documents d’archives, est présenté dans le dernier numéro 312 de la revue En Direct !
L’article est consultable au lien suivant : https://tinyurl.com/2d8uypym
🎓 Soutenances de mémoire - Session 2
La deuxième session des soutenances des mémoires des étudiants en Master TAL a lieu le mardi 02 juillet à Préclin
🎓 Soutenances de mémoire - Session 1
Les soutenances des mémoires des étudiants en Master TAL auront lieu comme suit :
- Session 1 : le lundi 27 mai au Grand Salon
- Session 2 : le mardi 02 juillet à la Salle Préclin
📢 Dates importantes de la campagne de candidatures 2024 pour le Master TAL
Les candidatures au Master TAL clôturent le 24 mars
- Du 26/02/2024 au 24/03/2024 - Phase de dépôt des candidatures sur Mon Master - parcours Traitement Automatique des Langues (lien)
- Du 02/04/2024 au 28/05/2024 - Phase d'examen des candidatures
- Du 04/06/2024 au 24/06/2024 - Phase principale d'admission
Retrouvez le calendrier des candidatures ici : Lien calendrier Mon Master.
Pour plus d'informations, consultez http://tesniere.univ-fcomte.fr/master.html et contactez iana.atanassova@univ-fcomte.fr.
Quatrième édition de la Journée d'études TEDonnées
Vendredi 12 avril 2024, MSHE
Quatrième édition de la journée d’étude TEDonnées
Échanger et innover : les SHS à l’horizon du numérique
Ces dernières années, l’accès aux collections de documents d’archives a été simplifié grâce aux campagnes de numérisations massives, menées par les bibliothèques et les archives, et a permis l’émergence de grands corpus en Sciences Humaines et Sociales (SHS). Le numérique a également poussé au développement de nouvelles méthodes de travail, comme la lecture distante, et l’émergence de domaines interdisciplinaires, tels que les Humanités Numériques ou la Géomatique. Récemment, l’intelligence artificielle et les modèles de langue avancés tels que ChatGPT ont apporté d’importantes innovations méthodologiques, comme l’aide à la rédaction ou la génération de contenus. Cependant, ces outils présentent des inconvénients, par exemple l’usage inapproprié, sans réelle compréhension, des contenus automatiquement créés, ou le risque de désinformation par la création de faux contenus informationnels (appelés « hallucinations »).
Ainsi, quel est l’impact de la prédominance numérique sur la recherche en Sciences Humaines et Sociales, notamment en littérature, histoire et linguistique ? En effet, le numérique impose des choix et des limitations méthodologiques forts qui peuvent bouleverser les approches traditionnelles. De plus, ces technologies évoluent très vite. Il est donc difficile de prendre du recul et de réfléchir à leur impact, tout comme il est difficile de s’y former et de les intégrer aux méthodes de recherche en SHS. Comment les SHS se positionnent-elles par rapport au numérique ? Comment et où peuvent-elles s’y former, et surtout, dans quelle mesure peuvent-elles l’intégrer à leurs méthodologies ?
La journée est gratuite et ouverte à tout public.
Inscription :
L'inscription à la journée d’études TEDonnées se fait au lien suivant : lien formulaire d'inscription
Lien vers la visio conférence : https://tinyurl.com/2hkm7psc
Pour plus d'informations : site web TEDonnées 2024
💡 Prochains séminaires en TAL
Vendredi 05 avril 2024, de 9h à 12h, salle Préclin
Hugues de Mazancourt
CTO, Co-fondateur de Datapolitics, Paris
Expert NLP et IA
1) Datapolitics: une startup spécialisée dans l’analyse de la parole publique
Résumé : Présentation de la technologie et des enjeux de l’analyse automatique des débats publics, collectés tant au niveau national qu’au niveau local: chaîne d’acquisition, conversion de textes ou de flux video, extraction d’information, identification des parties prenantes et des prises de position, synthèse, … Nous aborderons également les aspects métiers et éthiques des traitements mis en jeu.
2) Ethique et NLP
Résumé : L’IA, et plus particulièrement le traitement automatique des langues, soulèvent de plus en plus fréquemment des questions éthiques (et des peurs associées), sans que les concepts soient toujours clairement définis. Nous présenterons un panorama de ces questions sans nous restreindre aux sujets des « fake news » ou des biais des modèles de langue, qui éclipsent bien souvent des questions plus importantes, en particulier lorsqu’il s’agit de mettre en œuvre ces technologies à l’échelle industrielle.

💡 Prochains séminaires en TAL
Vendredi 29 mars 2024, de 9h à 12h, Salle Préclin
Frédéric Landragin
Directeur de recherche au CNRS, spécialisé en linguistique et en TAL, Lattice, ENS Paris, Université Sorbonne Nouvelle
Comment parle un robot ? Quand la Science-Fiction anticipe ChatGPT
Résumé:
- Les machines parlantes sont partout, dans la science-fiction – de Planète interdite jusqu’à Ex_Machina en passant par Star Wars et Terminator – et dans la vie de tous les jours, avec les androïdes Pepper ou Nao, les assistants vocaux Siri ou Cortana, et le fameux ChatGPT qui fait l’actualité, jusqu’à donner une visibilité inespérée au domaine de recherche qu’est le traitement automatique des langues. Comment se faire comprendre de ces machines ? Et comment, elles, nous comprennent-elles ? Quels sont les algorithmes informatiques en jeu ? Que penser des IA et des robots de la SF capables, à l’image de C-3PO, de maîtriser six millions de formes de communication ? La machine qui comprend tout et parle avec pertinence est-elle à portée de main ?
💡 Prochains séminaires en TAL
Vendredi 22 mars 2024, de 10h à 13h, D12
Dominique Mariko
Lead Data Scientist, Yseop, Paris
TAL et conformité logicielle
Résumé:
- Présentation de l'entreprise Yseop et de la stack hybride ;
- Discussion sur les problématiques de mise en production des systèmes d'IA pour l'industrie régulée et plus généralement, état des projets de lois et régulations à date ;
- En relation, présentation détaillée des problématiques liées à l'évaluation des modèles de langue en production et points techniques associés.
📌 Présentations des mémoires de Master 2 TAL
Les étudiants du Master 2 TAL présenteront leurs travaux de mémoire le mardi 19 mars de 9h à 12h en K09 (site Canot).Tous les étudiants en master et doctorat sont conviés à cette rencontre.
💡 Prochains séminaires en TAL
Mardi 12 mars 2024, de 9h à 12h, salle Préclin
Aurélie Nomblot
Doctorante en TAL, CRIT, Université de Franche-Comté
Vers la création d'un générateur de langues inventées : méthodologie et création de règles
Résumé:
Les langues inventées occupent une place de plus en plus significative dans les univers des séries télévisées, des films et des jeux vidéo, renforçant considérablement l'immersion des spectateurs et des joueurs. Ce séminaire explore les défis et les complexités que rencontrent les idéolinguistes dans la création de ces langues inventées. Nous explorerons les résultats d'une enquête détaillée qui vise à comprendre les méthodes, les besoins et les aspirations des idéolinguistes dans leurs processus d’invention de langues inventées. Par ailleurs, nous aborderons une méthode développée dans le cadre de cette thèse pour l'élaboration de règles linguistiques destinées à un outil de création automatique de langues.
Yagmur Ozturk
Doctorante en TAL, CRIT, Université de Franche-Comté
Morphosémantique du turc : création de ressources formalisées
Résumé:
En termes de ressources morphologiques, le turc se révèle être une langue sous-dotée dans le domaine de la morphologie dérivationnelle en Traitement Automatique des Langues (TAL) : il n'existe pas de ressources décrivant de manière formelle, en particulier en ce qui concerne les aspects sémantiques. Ce projet de recherche vise à décrire et à utiliser les ressources et études existantes pour développer un outil de TAL pour la dérivation nominale en turc. La première partie de notre étude présente les analyseurs morphologiques actuels, mettant en évidence une lacune dans la morphologie dérivationnelle des noms. Nous discutons ensuite de la manière dont les morphèmes dérivationnels, en particulier les morphèmes nominaux, sont décrits dans les études linguistiques et des problèmes que cela pose pour une étude systématique. Enfin, nous présentons les ressources formalisées que nous avons créées pour une étude systématique des morphèmes de nom à nom : Semantürk, une ontologie des catégories sémantiques adaptée du typage sémantique des noms (Huguin et. al, 2023) mise en place pour l'annotation de la ressource morphologique sur la langue française Démonette (Namer et. al, 2023) ; et DerivBaseTR, une base de données de morphèmes avec des caractéristiques spécifiques, comme les ressources formalisées que nous avons créées pour une étude systématique des morphèmes de nom à nom.
Références :
Namer, F., N. Hathout, D. Amiot, L. Barque, O. Bonami, G. Boyé, B. Calderone, J. Cattini, S. Dal Maso, A. Delaporte, G. Duboisdindien, A. Falaise, N. Grabar, P. Haas, F. Henry, M. Huguin, J. Nyoman, L. Liégeois, S. Lignon, L. Macchi, G. Manucharian, C. Masson, F. Montermini, N. Okinina, F. Sajous, D. Sanacore, M. Thi Tran, J. Thuilier, Y. Toussaint and D. Tribout. (2023). « Démonette-2, a derivational database for French with broad lexical coverage and fine-grained morphological descriptions. » Lexique 33: 6-40, DOI:10.54563/lexique.1242, hal-04363595.
Huguin, M., L. Barque, P. Haas and D. Tribout. (2023). « Typage sémantique des noms dans la ressource morphologique Démonette. » Lexique: 33: 41-56, DOI:10.54563/lexique.1086, hal-04369075.
Vendredi 15 mars 2024, de 9h à 12h, salle Préclin
Laure Cataldo
Maîtresse de Conférence, CRIT, Université de Franche-Comté
Analyse de corpus en linguistique anglaise – approches méthodologiques et perspectives
Résumé:
Cette présentation abordera l’ensemble des corpus préalablement traités ou en cours de traitement dans le cadre de mes recherches en linguistique anglaise, qui s’inscrivent principalement dans l’analyse de discours, et questionnera la possibilité d’une exploitation de ces corpus dans un travail collaboratif avec des collègues spécialistes en traitement automatique des langues.
Nicolas Gutehrlé
Doctorant en TAL, CRIT, Université de Franche-Comté
Extraction et Modélisation ONTologique des Acteurs et Lieux pour la valorisation du patrimoine de la Bourgogne Franche-Comté
Résumé:
Ces dernières années, les bibliothèques et archives ont mené de nombreuses campagnes de numérisation de leurs collections. Si ces campagnes ont facilité l'ouverture et l'accessibilité des documents d'archives à un public plus large, leur découvrabilité et la valorisation de leurs contenus restent des tâches difficiles en raison du manque de structure des contenus textuels. Afin de permettre l'exploration, l'exploitation et la valorisation des « données massives du passé » (Kaplan et Di Lenardo, 2017), il est nécessaire de structurer le contenu textuel des documents historiques par l’ajout d’annotations sémantiques.
Dans cette présentation, nous aborderons la tâche de l’extraction jointe d’entités et de relations (Joint Extraction of Relations and Entities), qui vise à extraire de façon jointe les entités nommées et leurs relations dans un contenu textuel. Nous présenterons l’approche ELIJERE (Extensible, Lightweight and Interpretable Joint Extraction of Relations and Entities), une nouvelle approche pour la tâche de l’extraction jointe d’entités et de relations. Cette approche repose l’emploi de ressources linguistiques permettant d’extraire et de catégoriser depuis une phrase les entités impliquées dans une relation.
Nous présenterons tout d’abord cette méthode, avant de présenter son évaluation sur un corpus de données contemporaine, puis sur un corpus de documents historiques publiés en Bourgogne et en Franche-Comté au 19ème et 20ème, collectés dans le cadre du projet EMONTAL. Cette présentation sera suivie par une discussion sur les futurs pistes de travail pour la tâche de l’extraction jointe d’entités et de relations.
💡 Prochains séminaires en TAL
Vendredi 08 mars 2024, de 9h à 12h en Amphi Petit
Panggih Kusuma Ningrum
Doctorante en TAL, CRIT, Université de Franche-Comté
Introducing UnScientify: A web application for detecting scientific uncertainty in scientific texts
Résumé:
The ANR InSciM project, in collaboration with GESIS, has culminated in the development of UnScientify, a web application designed to enhance the detection of scientific uncertainty in scholarly texts. This interactive system leverages a weakly supervised technique that incorporates a fine-grained annotation scheme to detect verbally formulated uncertainties in scientific documents. The core methodology of UnScientify is founded on a complex pipeline that integrates span patterns matching, complex sentence analysis and author reference checking. This approach streamlines the labelling and annotation processes essential for identifying scientific uncertainties, covering a variety of uncertainty expression types to support diverse applications including information retrieval, text mining and scientific document processing. UnScientify features interpretable results, allowing a deeper understanding of the nuances of scientific uncertainty identified in texts. The presentation will also include a live demonstration of UnScientify, demonstrating its capabilities and its potential to revolutionise the way scientific texts are analysed and understood.
Dates importantes de la campagne de candidatures 2024 pour le Master TAL
Du 26/02/2024 au 24/03/2024 : Dépôt des candidatures sur Mon Master
Retrouvez le calendrier des candidatures ici : Lien calendrier Mon Master.
Pour plus d'informations, consultez http://tesniere.univ-fcomte.fr/master.html et contactez iana.atanassova@univ-fcomte.fr.
🧑💻 Présentations des mémoires de Master 1 TAL
Les étudiants du Master 1 TAL présenteront leurs travaux de mémoire le vendredi 16 février de 9h à 12h au Salon Préclin puis de 14h à 16h au Grand Salon.Tous les étudiants en master et doctorat sont conviés à cette rencontre.
💡 Prochain séminaire en TAL
Vendredi 26 janvier 2024, de 10h à 13h au Grand Salon
Juyeon Kang
Head of Data Science, Fortia Financial Solutions, Paris
Extraction d’informations à partir des données non structurées
Résumé: Dans cette présentation seront abordés les différentes approches de l’extraction d’informations à base des techniques de l’IA. Nous prenons comme use case les problématiques rencontrées lors de l’extraction des informations dans les documents financiers. Nous pourrons également aborder le sujet de la construction des datasets ainsi que la méthode/outil d’annotation exploitée dans un contexte industriel.
Participation au Networking & Training Workshop

Vendredi 15 décembre 2023, Session 3, Amphithéâtre MSHE
Dr. Iana Atanassova interviendra au Networking & Training Workshop sur la mise en place du projet portant sur l'incertitude ‘A Journey into Scientific Uncertainty: Building a Project of Excellence in the Human and Social Sciences’. Pour plus d'information : https://actu.univ-fcomte.fr/agenda/projet-greci-colloque-du-14-15-decembre-2023
🎓Doctorat, docto... WHAT ? Témoignages en Bourgogne-Franche-Comté

Les doctorants en Traitement Automatique des Langues ont participé à une vidéo sur la valorisation du doctorat : cliquer ici.
Thèse : Salah Yahiaoui, Extraction et catégorisation de l’information temporelle de textes scientifiques

Nous avons le plaisir d'annoncer la soutenance de thèse de notre doctorant Salah Yahiaoui qui se tiendra le 08 décembre à 8h30 au Grand Salon (UFR SLHS). La thèse porte sur l'Extraction et catégorisation de l’information temporelle de textes scientifiques et est dirigée par Iana Atanassova. Le jury sera composé de :
- Professeur Cyril LABBÉ, LIG, Université Grenoble Alpes
- Professeur Guillaume CABANAC, IRIT, Université Toulouse 3 ; IUF
- Professeure émérite Sylviane CARDEY, CRIT, Université de Franche-Comté ; IUF
- Professeur émérite Mohamed HASSOUN, ENSSIB
- Dr. Marc BERTIN, ELICO, Université Lyon 1
- Dr. Iana ATANASSOVA, CRIT, Université de Franche-Comté
Résumé de la thèse : Cette thèse aborde la problématique du traitement de corpus scientifiques, d’un point de vue linguistique, afin d’en extraire, catégoriser et agréger les informations spatiotemporelles pour produire de nouvelles représentations de l’information textuelle. Dans un premier temps, nous proposons le schéma d'annotation TimeInfo, qui permet de rendre compte de la sémantique des différentes expressions temporelles dans les textes scientifiques. Nous montrons l'apport de TimeInfo par rapport aux schémas d'annotation existants, notamment TimeML. Dans un deuxième temps, nous construisons des ensembles de règles linguistiques pour l'annotation automatique des corpus scientifiques avec TimeInfo. Nous traitons le corpus CORD-19 et produisons un nouveau corpus annoté, TimeTank. Enfin, nous proposons des applications autour de TimeInfo et abordons la problématique des informations spatiales, par une expérimentation sur leur annotation et cartographie.
Fête de la science
 Tous les ans, les sciences ont leur fête pendant laquelle rencontres, découvertes, expériences et visites sont au programme. L'université de Franche-Comté vous accueille avec 2 après-midi, du 14/10 au 15/10, réservés pour tous les curieux. Nos doctorants ainsi que notre ingénieure de recherche seront présents sur le Campus de la Bouloie de 14h à 18h. Programme court ou détaillé
Tous les ans, les sciences ont leur fête pendant laquelle rencontres, découvertes, expériences et visites sont au programme. L'université de Franche-Comté vous accueille avec 2 après-midi, du 14/10 au 15/10, réservés pour tous les curieux. Nos doctorants ainsi que notre ingénieure de recherche seront présents sur le Campus de la Bouloie de 14h à 18h. Programme court ou détaillé
Valorisation de la recherche - 600 ans de l'UFC

Nos doctorants à la nuit des chercheurs

Présentation du dispositif PEPITE BFC
Mme Avrile LAUBERT, chargée de sensibilisation et d'accompagnement entrepreneurial, présentera le dispositif PEPITE BFC en faveur de l'entreprenariat le jeudi 05 octobre 2023 de 9h à 10h en salle H23.

Réunion de rentrée du master TAL 1 & 2

La réunion de rentrée du master TAL pour l'année 2023-2024 aura lieu le jeudi 07 septembre 2023 de 14h à 16h en salle C23.
Annonce
Toutes nos félicitations au docteur François-Claude Rey pour l'obtention d'un contrat post-doctoral d'un an comme docteur-entrepreneur ! Il rejoindra l'équipe du département TAL du C.R.I.T. à partir du 1er septembre 2023
Annonce
Toutes nos félicitations à Yağmur Öztürk pour l'obtention d'un poste d'ATER en TAL au laboratoire C.R.I.T. !
Soutenances des mémoires en TAL

Les soutenances des mémoires des étudiants en Master TAL auront lieu comme suit :
- Session 1 : le lundi 22 mai de 09h à 13h au Grand Salon
- Session 2 : le jeudi 29 juin de 09h à 13h au Grand Salon
Annulation du séminaire en TAL
Nous sommes au regret d'annoncer que le séminaire Traitement automatique d’une langue peu dotée : l’exemple du quechua, par Johanna Cordova (ERTIM, INALCO) de ce jeudi 06 avril 2023 est annulé.
Nous ferons en sorte qu'il prenne place lors des séminaires en TAL du CRIT de l'année prochaine.
Nous nous excusons pour toutes gênes occasionnées.
Prochain séminaire en TAL
Jeudi 06 avril 2023, de 14h à 16h30, E13
Johanna Cordova,
ERTIM, INALCO
Traitement automatique d’une langue peu dotée : l’exemple du quechua
Résumé: Les langues quechua sont parlées dans 7 pays d’Amérique du Sud et regroupent plus de 6 millions de locuteurs. Malgré sa grande expansion, le quechua est une langue peu dotée, et qui reste peu étudiée du point de vue du TAL. Nous présenterons quelques éléments de morphologie du quechua, langue de typologie agglutinante, et étudierons quelques solutions mises en place pour doter la langue des outils élémentaires pour le TA.
Annulation du séminaire en TAL
Nous sommes au regret d'annoncer que le séminaire En quoi est-ce complexe d'inventer une langue ? Du charabia vers une structure linguistiquement plausible, par Aurélie Nomblot (doctorante en Traitement Automatique des Langues, CRIT, université de Franche-Comté) et La sémantique des suffixes nominaux : création d’une ontologie pour le turc par Yağmur Öztürk (doctorante en Traitement Automatique des Langues, CRIT, université de Franche-Comté) de ce vendredi 31 mars est annulé.
Nous ferons en sorte qu'il prenne place lors des séminaires en TAL du CRIT de l'année prochaine.
Nous nous excusons pour toutes gênes occasionnées.
Prochain séminaire en TAL
Vendredi 31 mars 2023, de 9h30 à 12h, Grand Salon
Aurélie Nomblot
doctorante en Traitement Automatique des Langues, CRIT, université de Franche-Comté
En quoi est-ce complexe d'inventer une langue ? Du charabia vers une structure linguistiquement plausible.
Résumé: Ce séminaire répond à cette question en examinant les choix de création pour les différents aspects d’une langue tels que la phonologie, la grammaire, le lexique et l'évolution de la langue. Il explore également la façon dont une langue créée peut refléter les traits d'un groupe fictif, et présente enfin une méthodologie pour créer un générateur de langues inventées.
Yağmur Öztürk
doctorante en Traitement Automatique des Langues, CRIT, université de Franche-Comté
La sémantique des suffixes nominaux : création d’une ontologie pour le turc.
Résumé: Ce séminaire portera sur la mise en place de ressources pour la réalisation d’une analyse morphosémantique des noms dérivés à partir d’une base nominale. Nous présenterons tout d’abord, la création d’un inventaire de morphèmes nominaux et la formalisation de leur description. Puis, nous nous concentrerons plus spécifiquement sur la représentation du(des) sens porté(s) par ces morphèmes. Pour cela, nous avons réalisé une expérimentation sur un ensemble de catégories sémantiques appliquées aux morphèmes dérivationnels, proposées par Bagasheva (2018) et décrites comme universelles, produit pour la description d’affixes dérivationnels. Suite à cette expérimentation, nous avons conclu que cet ensemble n’est pas suffisant pour la description des morphèmes dérivationnels du turc. Étant donné qu’il n’existe pas de ressources de catégories sémantiques pour la description des morphèmes dérivationnels, nous avons déduit la nécessité de construire une ontologie de catégories sémantiques, basée sur des critères spécifiques (dont l’interopérabilité des données) que nous présenterons durant ce séminaire.
Bagasheva, A.,« Comparative semantic concepts in affixation ». In: Salvador Valera & Juan Santana (eds.), Competing Patterns in English Affixation, 33-65. Peter Lang, 2018.
Annulation du séminaire en TAL
Nous sommes au regret d'annoncer que le séminaire Extraction d’informations à partir des données non structurées, par Juyeon Kang (Head of Data Science, Fortia Financial Solutions) de ce vendredi 24 mars est définitivement annulé.
Nous ferons en sorte qu'il prenne place lors des séminaires en TAL du CRIT de l'année prochaine.
Nous nous excusons pour toutes gênes occasionnées.
Festival de vulgarisation scientifique OVNI
Notre doctorant Nicolas Gutehrlé présentera ses travaux de recherche produits dans le cadre du projet EMONTAL lors du festival de vulgarisation scientifique OVNI à Morteau le 01 avril de 14h à 18h. Venez nombreux !
Prochain séminaire en TAL
Vendredi 24 mars 2023, de 9h30 à 12h, Salon Préclin
Juyeon Kang
Head of Data Science, Fortia Financial Solutions, Paris
Extraction d’informations à partir des données non structurées
Résumé: Dans cette présentation seront abordés les différentes approches de l’extraction d’informations à base des techniques de l’IA. Nous prenons comme use case les problématiques rencontrées lors de l’extraction des informations dans les documents financiers. Nous pourrons également aborder le sujet de la construction des datasets ainsi que la méthode/outil d’annotation exploitée dans un contexte industriel.
Prochain séminaire en TAL
Vendredi 17 mars 2023, de 9h30 à 12h, Salon Préclin
Iana Atanassova
maître de conférence HDR, IUF, CRIT, université de Franche-Comté
La recherche en pratique : étude sur le multilinguisme des publications scientifiques
Résumé: Nous proposons une étude sur les langues utilisées dans la base plurilingue d'articles scientifiques ISTEX qui contient plus de 50 langues. Nous étudions les relations de citation qui existent entre ces langues. Les résultats montrent une grande préférence pour les citations en anglais, qui prédomine parmi les sources citées même dans les articles écrits en d'autres langues. Dans une perspective plus pédagogique, ce séminaire aura pour objectif de montrer toutes les étapes de la construction d'une étude scientifique, les problèmes rencontrés et leurs solutions en s'appuyant sur les contenus enseignés en master TAL.
Nouvelles dates pour les candidatures au Master TAL
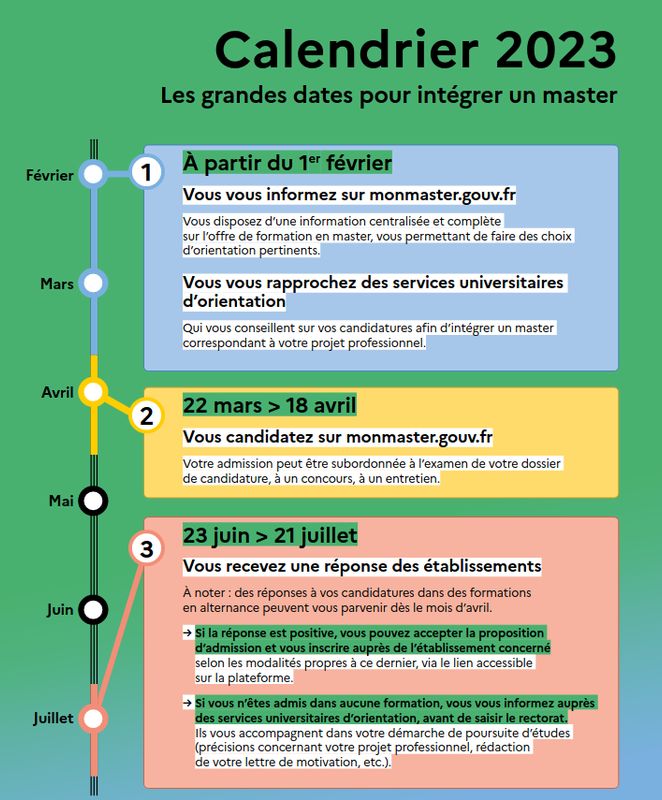
Du 22/03/2023 au 18/04/2023 : Dépôt des candidatures sur Mon Master
Du 23/06/2023 au 21/07/2023 : Publication des résultats, confirmation et inscription.
Retrouvez le calendrier des candidatures ici : http://tesniere.univ-fcomte.fr/ressources/Calendrier_MM.pdf.
Pour plus d'informations, consultez http://tesniere.univ-fcomte.fr/master.html et contactez iana.atanassova@univ-fcomte.fr.
Prochain séminaire en TAL
Vendredi 03 mars 2023, de 9h45 à 12h45, Salon Préclin
Luca Nobile
maître de conférence, CPTC, université de Bourgogne
L'iconicité phonologique dans tous ses états : expériences, descriptions, méthodes, théories, enjeux
Résumé: Le séminaire tentera de fournir un aperçu d’ensemble du domaine scientifique de l'iconicité phonologique. On essayera de réunir les principales évidences expérimentales et descriptives, d’exemplifier le débat contemporain entre neurosciences et sciences du langage, et d’esquisser un cadre théorique et méthodologique suffisamment complexe pour répondre aux défis posés par les faits observables… et par les observateurs les plus sceptiques. On proposera enfin une mise en perspective historico-épistémologique pour inviter à repenser le rapport entre arbitraire et motivation dans le cadre des grandes tendances qui animent l'histoire de la pensée occidentale, notamment en matière de rapport entre oralité et écriture, langage et réalité, et nature et culture.
Mobilité Internationale des Doctorants
Félicitations à notre doctorante Panggih Kusuma Ningrum pour l'obtention d'une bourse Chrysalide Mobilité Internationale des Doctorants (MID) ! Cette bourse permettra d'établir une coopération internationale avec le laboratoire GESIS de l'Institut Leibnitz en Allemagne
Stages
Bienvenue à nos deux nouveaux stagiaires en master TAL, Emel Dalgic de l’université catholique de Louvain et Bruno de Brito de l’université de Franche-Comté, qui nous accompagnerons pour une durée de 6 et 2 mois respectivement !
Prochain séminaire en TAL
Vendredi 03 février 2023, de 9h30 à 12h, Grand Salon
Ali Sassane
maître de conférence HDR, Université 20 août 1955 de Skikda, Algérie
La psycholinguistique et la neurolinguistique entre théorie, pratique et perspectives
Résumé: La psycholinguistique et la neurolinguistique sont deux domaines d'étude scientifique interdisciplinaires qui collaborent régulièrement avec d’autres sciences à savoir, la linguistique, la psychologie et les neurosciences, etc. Ces deux disciplines ont l'ambition d’employer les nouvelles technologies les plus récentes (EEG, IRMf), ainsi que des techniques expérimentales approuvées telles que: l'écoute dichotique, amorçage sémantique, etc. J'aborderai ces disciplines au travers de mes propres recherches ainsi que de quelques publications pour mieux susciter leurs intérêts, notamment, par le biais de la Sémantique Cognitive.
Prochain séminaire en TAL
Vendredi 27 janvier 2023, de 9h30 à 12h, Grand Salon
Marc BERTIN
ELICO, Université Claude Bernard Lyon-1
1) PNSO2 "Deuxième Plan national pour la science ouverte"
Résumé : Dans le cadre de la présentation du Deuxième Plan national pour la science ouverte nous évoquerons les différents axes afin de généraliser les science ouverte en France. Nous rappellerons que la science ouverte est la diffusion sans entrave des résultats, des méthodes et des produits de la recherche scientifique. Nous discuterons des opportunités que représente la mutation numérique pour développer l’accès ouvert aux publications, aux données, aux codes sources et aux méthodes de la recherche.
2) ANR TheoCite : analyse des citations
Résumé : L'accès aux publications en texte intégrale nous offre de nouvelles possibilités de fouille de corpus. Le projet ANR Théoscit présentera et discutera de la compréhension des citations dans leur contexte. Il s'agit d'un problème non résolu en science de l’information. La complexité de cet objet d’étude, impose un dialogue transdisciplinaire entre bibliométriciens, linguistes, sociologues et informaticiens. Ce projet vise à dresser une typologie des contextes de citations afin de mieux expliquer les actes de citations et d’établir les bases fonctionnelles de leurs utilisations. Ce dialogue transdisciplinaire conduira à la proposition d’un modèle conceptuel des actes de citation ainsi qu’à l’élaboration d’un prototype d’identification, d’extraction et de classification.
Publication : Bulletin de Linguistique Appliquée et Générale (BULAG)
 N° 40 : Languages Analysis, Comparison and Generation Systems, Models and Applications : Homage to Peter GREENFIELD (2022), coordonné par S. Cardey, F-C. Rey, I. Atanassova
N° 40 : Languages Analysis, Comparison and Generation Systems, Models and Applications : Homage to Peter GREENFIELD (2022), coordonné par S. Cardey, F-C. Rey, I. AtanassovaRésumé : The contributions gathered in this special number of the BuLAG deal with linguistics, computer science and natural language processing, where numerous languages are represented as well as many diverse applications. Are discussed models for the analysis and generation of languages and concrete descriptions and also comparisons between natural languages and constructed languages (similarities, divergences inter-languages and intra- language). The researches presented here are based on the fundamental domains of linguistics and computer science with their interrelations and developments.
Mots-clés : Traitement automatique des langues, Industries des langues, Natural Language Processing, Human Language Technology
Appel à communication : The 17th NooJ International Conference 2023
L'Université de Zadar (Département de Philologie Classique et Département des Sciences de l'Information), en coopération avec le Centre de Recherches Interdisciplinaires et Transculturelles (C.R.I.T.) de l'Université de Franche-Comté (Besançon) et l'association NooJ sont heureux de vous inviter à la 17ème Conférence Internationale NooJ 2023 qui se tiendra du 31 mai au 2 juin 2023 à Zadar (Croatie).
Retrouvez toutes les informations et l’appel à communication sur le site de l’événement.
Prochain séminaire en TAL
Vendredi 20 janvier 2023, de 9h30 à 12h, Grand Salon
Panggih Kusuma Ningrum
doctorante, CRIT, université de Franche-Comté
Processing Scientific Uncertainty
Résumé : Scientific uncertainty is an integral part of the research process and inherent to the construction of new knowledge. We examine the ways uncertainty is expressed in articles and propose a new interdisciplinary annotation framework to categorize sentences that contain uncertainty.
Candidatures 2023 pour le Master TAL : Dates importantes
20/04/2023 : Début des dépôts des candidatures eCandidat
23/05/2023 : Fin des dépôts des candidatures
21/06/2023 : Publication des résultats
28/06/2023 : Confirmation et inscription
Pour plus d'informations, consultez http://tesniere.univ-fcomte.fr/master.html et contactez iana.atanassova@univ-fcomte.fr.
Stages : Traitement de textes scientifiques pour la catégorisation d'expressions d'incertitude (6mois)

Venez travailler avec nous sur la catégorisation de l'incertitude scientifique dans les publications en anglais. Nous proposons plusieurs stages sur le traitement de corpus scientifiques avec pour objectif le développement d'algorithmes pour l'extraction et la catégorisation des expressions d'incertitude. Vous travaillerez au sein d'une équipe internationale de chercheurs.
Ces stages s'adressent aux étudiants en Master TAL, Informatique ou disciplines similaires. Pour plus de détails, consultez http://tesniere.univ-fcomte.fr/ressources/offre-stage-InSciM-nov2022.pdf.
Stages : Développement d’un outil de correction de réponses à un examen (start-up E-cole)

Plusieurs stages (de 4 à 6 mois) sont proposés par notre laboratoire en partenariat avec la start-up E-Cole. L’objectif du projet est de développer un algorithme de traitement de réponses aux exercices en texte libre, afin de proposer des fonctionnalités d’évaluation automatique.
Les stages sont ouverts aux étudiants de niveau Master avec une formation en Informatique et Traitement Automatique des Langues. Pour plus de détails, consultez http://tesniere.univ-fcomte.fr/ressources/offre-stage-ecole-nov2022.pdf.
Présentations des mémoires de Master 2 TAL
Les étudiants du Master 2 TAL présenteront leurs travaux de mémoire le lundi 7 novembre de 14h à 16h au Salon Préclin.Tous les étudiants en master et doctorat sont conviés à cette rencontre.
Prochain séminaire du Centre Tesnière
Vendredi 08 avril 2022, de 9h30 à 12h, en présentiel (B16)
(https://rdv4.rendez-vous.renater.fr/seminaire-tal) Fouille sémantique de textes littéraires et médicaux : quelques réalisations
Motasem Alrahabi, , ingénieur de recherche et coordinateur scientifique de l'équipe-projet Obtic - Sorbonne Université
Offre de stage : Stage en linguistique de corpus
Durée : Trois mois
Lieu : Université de Bourgogne, Centre Interlangues – Texte, Image, Language (EA 4182)
et Université de Franche-Comté, Centre de Recherches Intertextuelles et Transculturelles, CRIT (EA 3224)
Cliquez ici pour voir l'annonce en détails
Dates importantes de la campagne de candidatures 2022 pour le Master TAL
20/04/2022 : Début des dépôts des candidatures sur l’application Mon Master
23/05/2022 : Fin des dépôts des candidatures
21/06/2022 : Publication des résultats
28/06/2022 : Confirmation et inscription
Pour plus d'informations, contactez iana.atanassova@univ-fcomte.fr.
Présentation du dispositif PEPITE BFC
Mme Avrile LAUBERT, chargé de sensibilisation et d'accompagnement entrepreneurial, présentera le dispositif PEPITE BFC en faveur de l'entreprenariat le jeudi 22 septembre 2022 de 12h à 13h au Grand Salon